About
Dr. R. Prabakaran is a computational biologist interested in how biomolecules evolve - in particular, the conformational dynamics, function, and interactions of proteins across the dark matter of microbial life. His work spans protein and DNA language models, graph neural networks, contrastive learning, and molecular simulation, and uses AI and representation learning to close gaps in our understanding of biology.
He currently develops AI methods for functional metagenomics as part of the ENIGMA project (including the REBEAN DNA language model), alongside reliability-aware prediction approaches such as the Random Neighbor Score. He is a member of the Bromberg Lab at Emory University.
Timeline
-
Postdoctoral Fellow
2023-Present
Bromberg Lab
Emory University, GA, USA -
Postdoctoral Associate
2022-2023
Bromberg Lab
Rutgers University, NJ, USA -
M.S. & Ph.D. in Computational Biology
2014-2022
Indian Institute of Technology Madras, India
Dissertation Title: Sequence and structural studies of aggregation prone regions in proteins: Development of a prediction method and large-scale analysis -
Associate - Functional test lead and analyst
2010-2014
Cognizant Technology Solutions, India
-
B. Tech. in Industrial Biotechnology
2006-2010
Anna University, India
Dissertation Title: Cloning and expression of the synthetic insulin gene in Kluyveromyces lactis expression system
Tool developments
Quantifying uncertainty in protein representations across models and tasks
"All models are wrong, ..." - we formulate Random Neighbor Score (RNS) to quantify the uncertainty of
biomolecule representations like protein, DNA or RNA - in a language model’s latent space.
Source: https://bitbucket.org/bromberglab/rns/src/main/
Publication: Prabakaran, R*., Bromberg, Y*. Quantifying uncertainty in protein representations across models and tasks. Nat Methods 23, 796–804 (2026)
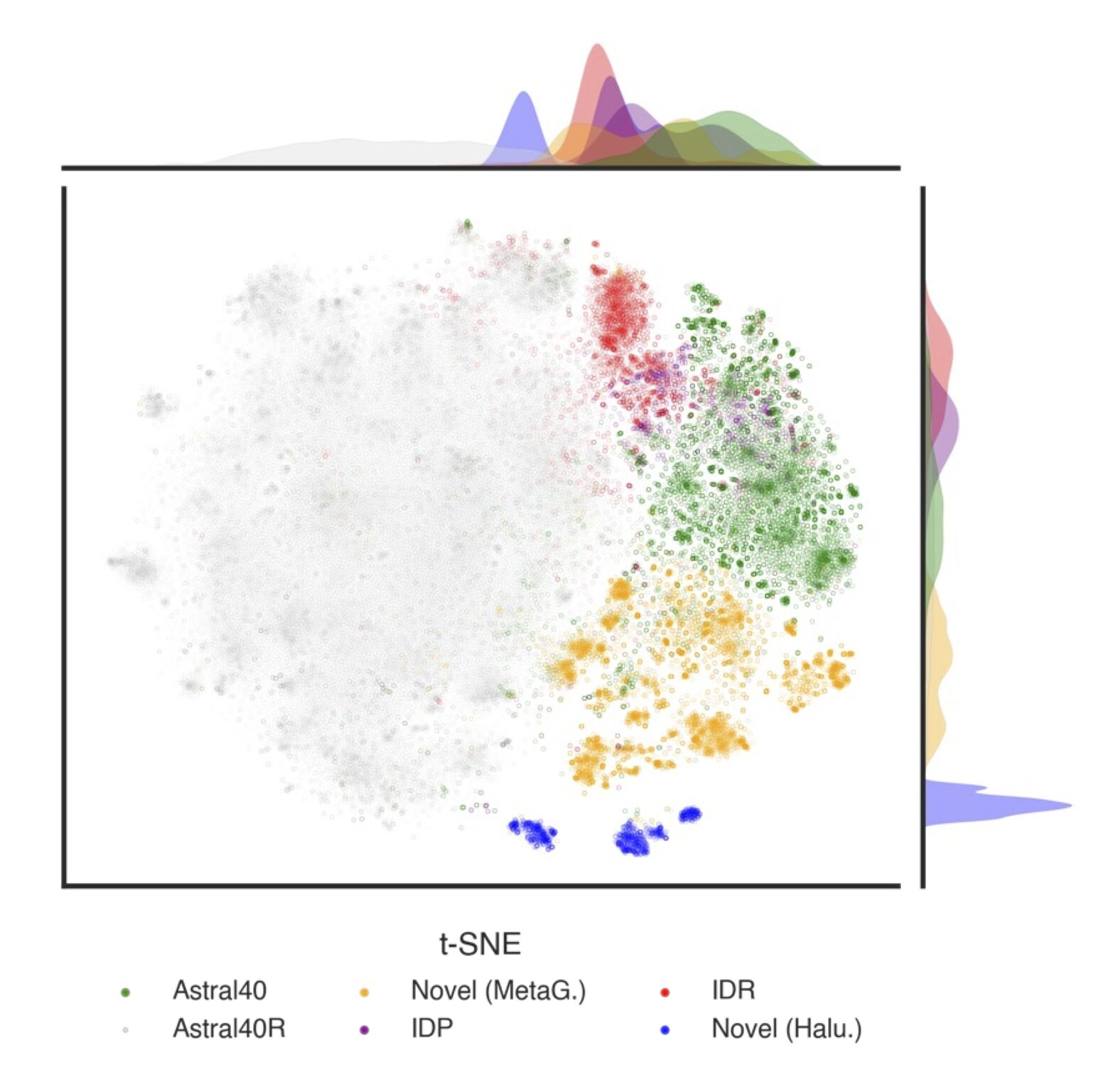
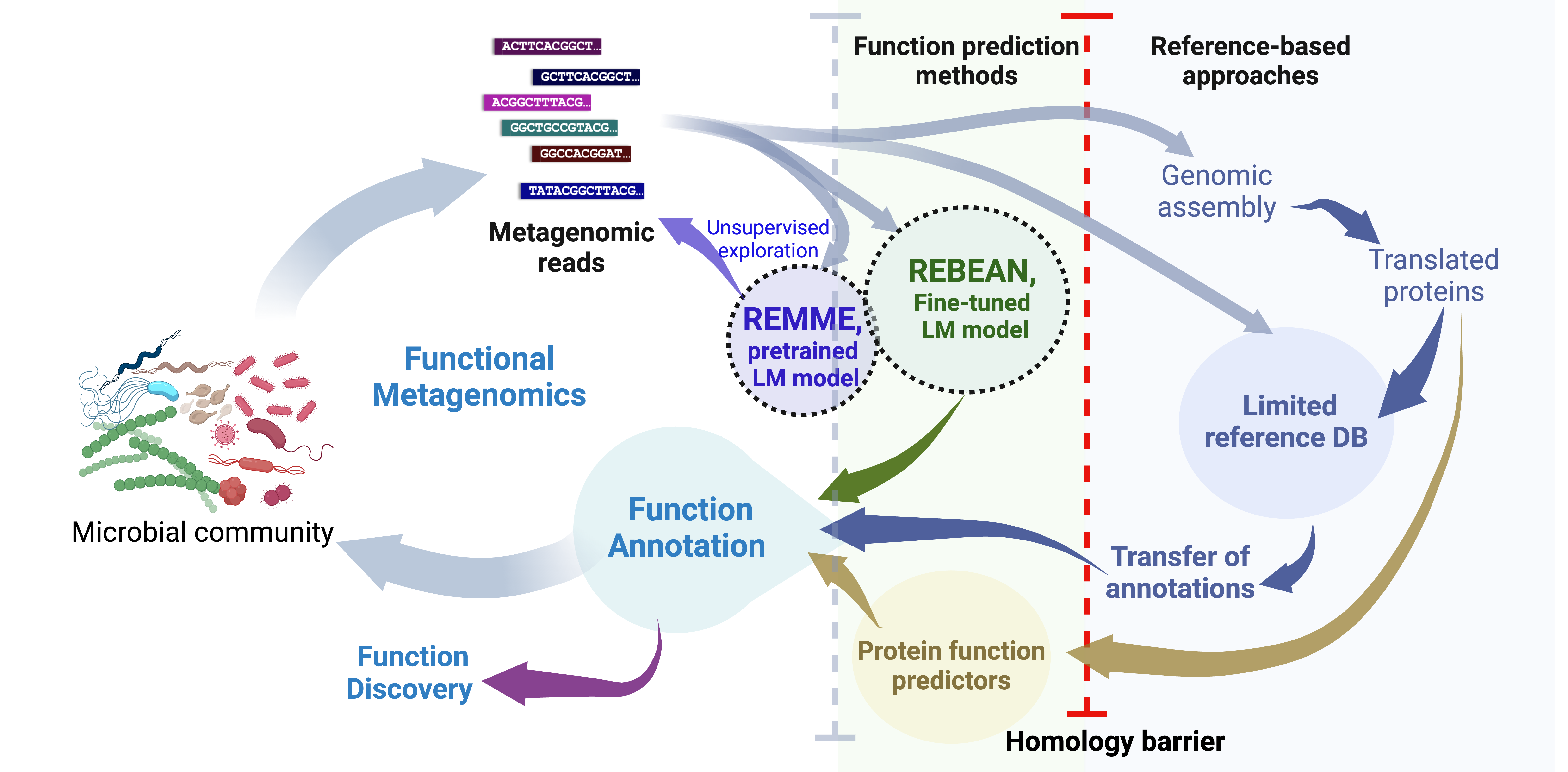
REBEAN: Read Embedding Based Enzyme ANnotation
REBEAN is a DNA language model for enzymatic annotation of sequencing reads. REBEAN is built for discovery of enzymatic function in both known and unknown sequence space mitigating drawbacks of alignment and translation-based approaches.
Webserver: https://services.bromberglab.org/rebean/submit
Source: https://bitbucket.org/bromberglab/rebeanpkg/src/main/
Publication: Prabakaran R* and Bromberg Y*, Deciphering enzymatic potential in metagenomic reads through DNA language models, Nucleic Acids Research, 53 (16), 2025, gkaf836
ANuPP: Aggregation Nucleation Prediction in Peptides and Proteins
Aggregation Nucleation Prediction in Peptides and Proteins (ANuPP) is an ensemble classifier developed and trained to identify amyloid-fibril forming peptides and regions in protein sequences.
Webserver: https://web.iitm.ac.in/bioinfo2/ANuPP/
Source (private): https://github.com/rpkarandev/ANuPP
Publication: Prabakaran R, Rawat P, Kumar S, & Michael Gromiha M (2021). ANuPP: A Versatile Tool to Predict Aggregation Nucleating Regions in Peptides and Proteins. Journal of molecular biology, 433(11), 166707.
NF-EnzymeFinder: end-to-end Nextflow pipeline for novel enzyme mining Unpublished
An end-to-end Nextflow pipeline that identifies enzymatic reads, assembles them into proteins, and delivers novel enzymes with predicted structures.
Source (private): https://github.com/rpkarandev/mag-rebean
Database developments
YAbS: The Antibody Society's Antibody Therapeutics Database
A manually curated resource offering detailed information on 1000+ therapeutic antibodies and their clinical status - developed by The Antibody Society.
Database: https://db.antibodysociety.org/
Publication: Rawat P, Crescioli S, Prabakaran R, Sharma D, Greiff V, & Reichert J M (2025). YAbS: The Antibody Society's antibody therapeutics database. mAbs, 17(1), 2468845.
Ab-CoV: A curated database for binding affinity and neutralization profiles of coronavirus-related antibodies
Ab-CoV contains manually curated experimental binding affinity (KD) and neutralization profile (IC50 and EC50) of coronavirus-related antibodies along with in silico mutational scanning of epitope and paratope region for known structures and viral protein features.
Database: https://web.iitm.ac.in/bioinfo2/ab-cov/
Publication: Rawat P, Sharma D, Prabakaran R, Ridha F, Mohkhedkar M, Janakiraman V, & Gromiha M M (2022). Ab-CoV: a curated database for binding affinity and neutralization profiles of coronavirus-related antibodies. Bioinformatics (Oxford, England), 38(16), 4051–4052.
CPAD 2.0: Curated Protein Aggregation Database
A curated database of aggregating peptides, proteins and aggregation prone regions.
Database: https://web.iitm.ac.in/bioinfo2/cpad2
Publication: Rawat P, Prabakaran R, Sakthivel R, Mary Thangakani A, Kumar S, & Gromiha M M (2020). CPAD 2.0: a repository of curated experimental data on aggregating proteins and peptides. Amyloid : the international journal of experimental and clinical investigation : the official journal of the International Society of Amyloidosis, 27(2), 128–133.
UniProt ProtT5-Uncertainty Landscape Unpublished
An uncertainty landscape of UniProt - 214,684,295 ProtT5 protein embeddings and their Random Neighbor Score (RNS) values and intrinsic dimensionalities (IDs) - a depiction of what is, and is not, learned by protein language models (pLMs).
Related: RNS, Nat Methods 23, 796–804 (2026)
Teaching experience
- 2024-2025 Guest Lecture - Introduction to Bioinformatics, Emory University, GA, USA
- 2023-2025 Mentored three undergraduates and master students on their thesis
- 2019 Crash courses - Programming using Python, Machine-learning and Statistics, Protein Bioinformatics lab, IIT Madras, India
- 2018-2021 Mentored two undergraduates on their Honour thesis
- 2018-2020 Teaching assistant - Bioinformatics: Algorithms and Applications, NPTEL, IIT Madras, India
- 2017 Workshop - "Data analysis and application of machine-learning for ligand binding affinity prediction using Python", BioFest 2017, IIT Madras, India
- 2015-2019 Teaching assistant - Computational Biology, IIT Madras, India
- 2015-2019 Teaching assistant - Bioinformatics, IIT Madras, India
Awards & service
- 2025 Travel grant - FMS4BIO25 workshop, AAAI Conference on Artificial Intelligence
- 2024 Travel grant - CSHL Biological Data Science meeting at NY, USA
- 2018-2022 Administrator for computing and web servers, Protein Bioinformatics Lab, IIT Madras, India
- 2014-2020 Awards - HTRA fellowship from Ministry of Human Resource Development (MHRD), Government of India during MS and PhD
- 2014 GATE Biotechnology (National level Aptitude test, India) - Rank 34
- 2010 GATE Biotechnology (National level Aptitude test, India) - Rank 14